Kafka如何避免消息丢失
Kafka消息框架通过broke来连接生产者和消费者,但是如果中间的某一个环节出现了故障,就会产生消息丢失的问题。针对消息丢失,我们可以从生产端、broke和消费端三个维度来处理。
生产端
生产端的职责就是,确保生产的消息能到达MQ服务端,这里我们需要有一个响应来判断本次的操作是否成功。
// 该方法会通过一个Callback函数,来判断消息是否发送成功,如果失败,我们需要补偿处理。
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
ACKS
-
acks=0,只要发送消息就认为成功,生产端不等待服务器节点的响应
-
acks=1,表示生产者收到 leader 分区的响应才会被认为发送成功
-
acks=-1(all):生产者发送过来的数据,只有当 ISR 中的副本全部收到消息时,生产端才会认为是成功的。这种配置是最安全的,但由于同步的节点较多,吞吐量会降低。(可靠性高,效率低;在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据, 对可靠性要求比较高的场景)
🤔 当acks=-1时,Leader收到数据,所有Follower都开始同步数据, 但有一个Follower,因为某种故障,迟迟不能与Leader进行同步,那这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set(ISR),意为和 Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)。
如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。例如2超时,这ISR变为(leader:0, isr:0,1)。这样就不用等长期联系不上或者已经故障的节点。
数据可靠性分析:如果分区副本设置为1个,或者ISR里应答的最小副本数量 ( min.insync.replicas 默认为1)设置为1,和ack=1的效果是一 样的,仍然有丢数的风险(leader:0,isr:0)。
因此数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
retries
retries:当消息发送出现错误的时候,系统会重发消息。retries 表示重试次数。默认是 int 最大值,2147483647。 如果设置了重试,还想保证消息的有序性,需要设置 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1 否则在重试此失败消息的时候,其他的消息可能发送成功了。
表示生产端的重试次数,如果重试次数用完后,还是失败,会将消息临时存储在本地磁盘,待服务恢复后再重新发送。建议值 retries=3
retry.backoff.ms
retry.backoff.ms:消息发送超时或失败后,两次重试之间的时间间隔,默认是 100ms。
消息重复
当生产端做完这些,一定能保证消息发送成功了,但可能发送多次,这样就会导致消息重复。
Kafka 0.11版本以后,引入了一项重大特性:幂等性。每条消息都有唯一的message id, MQ服务采用空间换时间方式,自动对重复消息过滤处理,保证接口的幂等性。重复数据的判断标准:具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。
- PID:Kafka每次重启都会分配一个新的pid
- Partition:分区号
- Sequence Number:序列号,单调自增
==所以幂等性只能保证的是在单分区单会话内不重复。==
🤔对于消费端,即使MQ服务中存储的消息没有重复,但消费端是采用拉取方式,如果重复拉取,也会导致
重复消费,如何解决这种场景问题?
方案一:只拉取一次(消费者拉取消息后,先提交 offset 后再处理消息),但是如果系统宕机,业务处理没有正常结束,后面再也拉取不到这些消息,会导致数据不一致,该方案很少采用。
方案二:允许拉取重复消息,但是消费端自己做幂等性控制。保证只成功消费一次。关于幂等技术方案很多,我们可以采用数据表或Redis缓存存储处理标识,每次拉取到消息,处理前先校验处理状态,再决定是处理还是丢弃消息。
broke
broke作为消息的存储介质,也有可能会丢失消息。比如:一个分区突然挂掉,那么怎么保证这个分区的数据不丢失,我们会引入副本概念,通过备份来解决这个问题,确保数据及时同步到多副本。
replication.factor
表示分区副本的个数,replication.factor >1 当leader 副本挂了,follower副本会被选举为leader继续提供服务。
min.insync.replicas
表示 ISR 最少的副本数量,通常设置 min.insync.replicas >1,这样才有可用的follower副本执行替换,保证消息不丢失
unclean.leader.election.enable
是否可以把非 ISR 集合中的副本选举为 leader 副本。
如果设置为true,而follower副本的同步消息进度落后较多,此时被选举为leader,会导致消息丢失,慎用。
消费端
消费端要做的是把消息完整的消费处理掉。但是这里面有个提交位移的步骤。
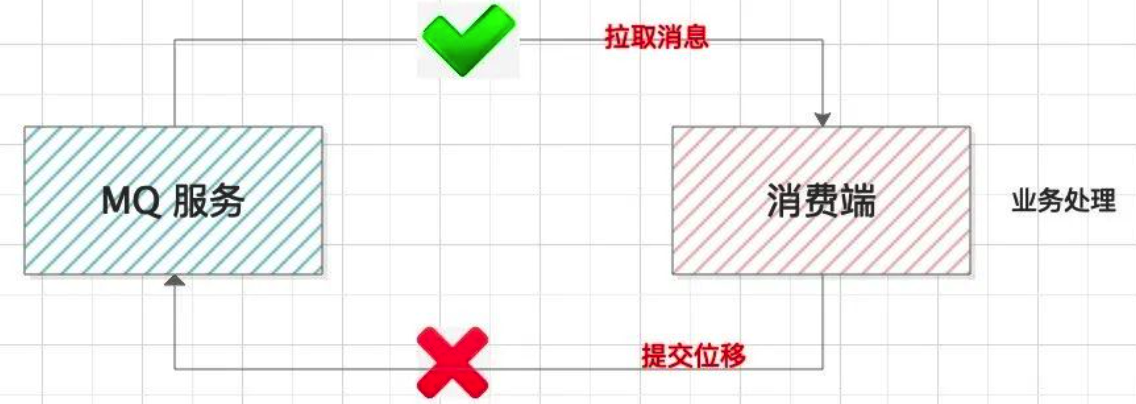
有的同学,考虑到业务处理消耗时间较长,会单独启动线程拉取消息存储到本地内存队列,然后再搞个线程池并行处理业务逻辑。这样设计有个风险,本地消息如果没有处理完,服务器宕机了,会造成消息丢失。
==正确的做法:拉取消息 –> 业务处理 –> 提交消费位移==
enable.auto.commit
表示消费位移是否自动提交。
如果拉取了消息,业务逻辑还没处理完,提交了消费位移但是消费端却挂了,消费端恢复或其他消费端接管该分片再也拉取不到这条消息,会造成消息丢失。所以,我们通常设置 enable.auto.commit=false,手动提交消费位移。
不过该方案同样也存在消息重复消费的问题,比如消费者拉取了消息4~消息8,业务处理后,在提交消费位移时,不凑巧系统宕机了,最后的提交位移并没有保存到MQ 服务端,下次拉取消息时,依然是从消息4开始拉取,但是这部分消息已经处理过了,这样便会导致重复消费。
既已览卷至此,何不品评一二: